Integration with multigrad
This notebook will show an example and discuss some of the complexity arising from performing kdescent in parallel with the aid of the multigrad package. We will be following an identical example to that found in the Advanced Usage section of the tutorial. All procedural differences will be flagged with a # NOTE: ... comment.
In the following script, the generate_model() function will do the same thing as before, except it will divide the sample size by the number of MPI ranks available, so that a fully-sized sample will be generated across all the ranks (and we will split the randkey between the ranks so the subsamples are not identical). Let’s save this script as kdescent-multigrad-integration.py:
"""
kdescent-multigrad-integration.py
"""
import functools
from dataclasses import dataclass
import numpy as np
import jax.numpy as jnp
import jax.random
import matplotlib.pyplot as plt
import seaborn as sns
from mpi4py import MPI
from diffopt import kdescent
from diffopt import multigrad
comm = MPI.COMM_WORLD
model_nsample = 20_000
data_nsample = 10_000 # same volume, but undersampled below logM* < 10.5
# Generate data weighted from two mass-dependent multivariate normals
@functools.partial(jax.jit, static_argnames=["undersample", "nsample"])
def generate_model(params, randkey, undersample=False, nsample=model_nsample):
# NOTE: Divide nsample and split randkey across MPI ranks:
nsample = nsample // comm.size
randkey = jax.random.split(randkey, comm.size)[comm.rank]
# Parse all 20 parameters
# =======================
# Lower and upper bounds on log stellar mass
logmlim = params[:2]
logmlim = logmlim.at[1].add(logmlim[0] + 0.001)
# Distribution parameters at lower mass bound
mean_mmin = params[2:4]
sigma11, sigma22 = params[4:6]
maxcov = jnp.sqrt(sigma11 * sigma22)
sigma12 = params[6] * maxcov
cov_mmin = jnp.array([[sigma11, sigma12],
[sigma12, sigma22]])
qfrac_mmin = params[7]
qmean_mmin = mean_mmin + params[8:10]
qscale_mmin = params[10]
# Distribution parameters at upper mass bound
mean_mmax = params[11:13]
sigma11, sigma22 = params[13:15]
maxcov = jnp.sqrt(sigma11 * sigma22)
sigma12 = params[15] * maxcov
cov_mmax = jnp.array([[sigma11, sigma12],
[sigma12, sigma22]])
qfrac_mmax = params[16]
qmean_mmax = mean_mmax + params[17:19]
qscale_mmax = params[19]
# Generate distribution from parameters
# =====================================
key1, key2 = jax.random.split(randkey, num=2)
triangle_vals = (0, 0.5, 1) if undersample else (0, 0, 1)
logm = jax.random.triangular(key1, *triangle_vals, shape=(nsample,))
logm = logmlim[0] + logm * (logmlim[1] - logmlim[0])
# Calculate slope of mass dependence
dlogm = logmlim[1] - logmlim[0]
dmean = (mean_mmax - mean_mmin) / dlogm
dcov = (cov_mmax - cov_mmin) / dlogm
dqfrac = (qfrac_mmax - qfrac_mmin) / dlogm
dqmean = (qmean_mmax - qmean_mmin) / dlogm
dqscale = (qscale_mmax - qscale_mmin) / dlogm
# Apply mass dependence
mean_sf = mean_mmin + dmean * (logm[:, None] - logmlim[0])
cov_sf = cov_mmin + dcov * (logm[:, None, None] - logmlim[0])
mean_q = qmean_mmin + dqmean * (logm[:, None] - logmlim[0])
qscale = qscale_mmin + dqscale * (logm - logmlim[0])
cov_q = cov_sf * qscale[:, None, None] ** 2
qfrac = qfrac_mmin + dqfrac * (logm - logmlim[0])
# Generate colors from two separate multivariate normals
rz_sf, gr_sf = jax.random.multivariate_normal(key2, mean_sf, cov_sf).T
rz_q, gr_q = jax.random.multivariate_normal(key2, mean_q, cov_q).T
# Concatenate the quenched + star-forming values and assign weights
data_sf = jnp.array([rz_sf, gr_sf, logm]).T
data_q = jnp.array([rz_q, gr_q, logm]).T
data = jnp.concatenate([data_sf, data_q])
weights = jnp.concatenate([1 - qfrac, qfrac])
return data, weights
# Define "true" parameters to generate training data
truth_logmmin = 9.0
truth_logmrange = 3.0
truth_mean_mmin = jnp.array([1.4, 1.1])
truth_var_mmin = jnp.array([0.7, 0.4])
truth_corr_mmin = 0.3
truth_qfrac_mmin = 0.2
truth_qmean_mmin = jnp.array([-0.1, 1.6])
truth_qscale_mmin = 0.3
truth_mean_mmax = jnp.array([2.0, 1.6])
truth_var_mmax = jnp.array([0.5, 0.5])
truth_corr_mmax = 0.75
truth_qfrac_mmax = 0.95
truth_qmean_mmax = jnp.array([-0.6, 1.2])
truth_qscale_mmax = 1.1
bounds_truth_logmrange = [0.001, jnp.inf]
bounds_var = ([0.001, jnp.inf], [0.001, jnp.inf])
bounds_corr = [-0.999, 0.999]
bounds_qfrac = [0.0, 1.0]
bounds_qmean_gr = [0.001, jnp.inf]
bounds_qscale = [0.001, jnp.inf]
truth = jnp.array([
truth_logmmin, truth_logmrange,
*truth_mean_mmin, *truth_var_mmin, truth_corr_mmin, truth_qfrac_mmin,
*truth_qmean_mmin, truth_qscale_mmin,
*truth_mean_mmax, *truth_var_mmax, truth_corr_mmax, truth_qfrac_mmax,
*truth_qmean_mmax, truth_qscale_mmax
])
guess = jnp.array([
9.25, 2.5, *[0.0, 0.0, 1.0, 1.0, 0.0, 0.5, 0.0, 1.0, 1.0]*2
])
bounds = [
None, bounds_truth_logmrange,
*[None, None, *bounds_var, bounds_corr, bounds_qfrac,
None, bounds_qmean_gr, bounds_qscale]*2
]
# Generate training data from the truth parameters we just defined
truth_randkey = jax.random.key(43)
training_x_weighted, training_w = generate_model(
truth, truth_randkey, undersample=True, nsample=data_nsample)
# NOTE: Every rank must be aware of the FULL training data, so we must gather:
training_x_weighted = jnp.concatenate(comm.allgather(training_x_weighted))
training_w = jnp.concatenate(comm.allgather(training_w))
# KDescent allows weighted training data, but to make this more realistic,
# let's use weighted sampling instead
training_selection = jax.random.uniform(
jax.random.split(truth_randkey)[0], (len(training_w),)) < training_w
training_x = training_x_weighted[training_selection]
# Define plotting function
lowmass_cut = [9.0, 9.5]
midmass_cut = [10.25, 10.75]
highmass_cut = [11.5, 12.0]
is_lowmass = ((lowmass_cut[0] < training_x_weighted[:, 2])
& (training_x_weighted[:, 2] < lowmass_cut[1]))
is_midmass = ((midmass_cut[0] < training_x_weighted[:, 2])
& (training_x_weighted[:, 2] < midmass_cut[1]))
is_highmass = ((highmass_cut[0] < training_x_weighted[:, 2])
& (training_x_weighted[:, 2] < highmass_cut[1]))
training_w_lowmass = training_w * is_lowmass
training_w_midmass = training_w * is_midmass
training_w_highmass = training_w * is_highmass
is_noweight_lowmass = (
(lowmass_cut[0] < training_x[:, 2])
& (training_x[:, 2] < lowmass_cut[1]))
is_noweight_midmass = (
(midmass_cut[0] < training_x[:, 2])
& (training_x[:, 2] < midmass_cut[1]))
is_noweight_highmass = (
(highmass_cut[0] < training_x[:, 2])
& (training_x[:, 2] < highmass_cut[1]))
def generate_model_into_mass_bins(params, randkey):
# NOTE: Gather data from each rank (since this is for plotting only)
model_x, model_w = generate_model(params, randkey=randkey)
model_x = jnp.concatenate(comm.allgather(model_x))
model_w = jnp.concatenate(comm.allgather(model_w))
is_low = ((lowmass_cut[0] < model_x[:, 2])
& (model_x[:, 2] < lowmass_cut[1]))
is_mid = ((midmass_cut[0] < model_x[:, 2])
& (model_x[:, 2] < midmass_cut[1]))
is_high = ((highmass_cut[0] < model_x[:, 2])
& (model_x[:, 2] < highmass_cut[1]))
return (model_x, model_x[is_low], model_x[is_mid], model_x[is_high],
model_w, model_w[is_low], model_w[is_mid], model_w[is_high])
def make_sumstat_plot(params, txt="", fig=None, prev_layers=None):
(modall, modlow, modmid, modhigh,
w_all, w_low, w_mid, w_high) = generate_model_into_mass_bins(
params, jax.random.key(13))
if prev_layers is not None:
for layer in prev_layers:
layer.remove()
fig = plt.figure(figsize=(10, 9)) if fig is None else fig
ax = fig.add_subplot(221) if len(fig.axes) < 4 else fig.axes[0]
ax.hist(training_x_weighted[:, 2], bins=50, color="red",
weights=training_w)
_, bins, hist1 = ax.hist(
modall[:, 2], color="grey", bins=50, alpha=0.9, weights=w_all)
hist2 = ax.hist(modlow[:, 2], bins=list(bins), color="C0",
alpha=0.9, weights=w_low)[-1]
hist3 = ax.hist(modmid[:, 2], bins=list(bins), color="C0",
alpha=0.9, weights=w_mid)[-1]
hist4 = ax.hist(modhigh[:, 2], bins=list(bins), color="C0",
alpha=0.9, weights=w_high)[-1]
ax.set_xlabel("$\\log M_\\ast$", fontsize=14)
text1 = ax.text(
0.98, 0.98, "Training data", color="red", va="top", ha="right",
fontsize=14, transform=ax.transAxes)
text2 = ax.text(
0.98, 0.91, txt, color="blue", va="top", ha="right",
fontsize=14, transform=ax.transAxes)
ax = fig.add_subplot(222) if len(fig.axes) < 4 else fig.axes[1]
hex1 = ax.hexbin(*modlow[:, :2].T, mincnt=1,
C=w_low, reduce_C_function=np.sum,
norm=plt.matplotlib.colors.LogNorm())
if prev_layers is None:
sns.kdeplot(
{"$r - z$": training_x_weighted[is_lowmass][:, 0],
"$g - r$": training_x_weighted[is_lowmass][:, 1]},
weights=training_w[is_lowmass],
x="$r - z$", y="$g - r$", color="red", levels=7, ax=ax)
ax.set_xlabel("$r - z$", fontsize=14)
ax.set_ylabel("$g - r$", fontsize=14)
text3 = ax.text(
0.02, 0.02, f"${lowmass_cut[0]} < \\log M_\\ast < {lowmass_cut[1]}$",
fontsize=14, transform=ax.transAxes)
ax = fig.add_subplot(223, sharex=ax, sharey=ax) if len(
fig.axes) < 4 else fig.axes[2]
hex2 = ax.hexbin(*modmid[:, :2].T, mincnt=1,
C=w_mid, reduce_C_function=np.sum,
norm=plt.matplotlib.colors.LogNorm())
if prev_layers is None:
sns.kdeplot(
{"$r - z$": training_x_weighted[is_midmass][:, 0],
"$g - r$": training_x_weighted[is_midmass][:, 1]},
weights=training_w[is_midmass],
x="$r - z$", y="$g - r$", color="red", levels=7, ax=ax)
ax.set_xlabel("$r - z$", fontsize=14)
ax.set_ylabel("$g - r$", fontsize=14)
text4 = ax.text(
0.02, 0.02, f"${midmass_cut[0]} < \\log M_\\ast < {midmass_cut[1]}$",
fontsize=14, transform=ax.transAxes)
ax = fig.add_subplot(224, sharex=ax, sharey=ax) if len(
fig.axes) < 4 else fig.axes[3]
hex3 = ax.hexbin(*modhigh[:, :2].T, mincnt=1,
C=w_high, reduce_C_function=np.sum,
norm=plt.matplotlib.colors.LogNorm())
if prev_layers is None:
sns.kdeplot(
{"$r - z$": training_x_weighted[is_highmass][:, 0],
"$g - r$": training_x_weighted[is_highmass][:, 1]},
weights=training_w[is_highmass],
x="$r - z$", y="$g - r$", color="red", levels=7, ax=ax)
ax.set_xlabel("$r - z$", fontsize=14)
ax.set_ylabel("$g - r$", fontsize=14)
text5 = ax.text(
0.02, 0.02, f"${highmass_cut[0]} < \\log M_\\ast < {highmass_cut[1]}$",
fontsize=14, transform=ax.transAxes)
ax.set_xlim(-4, 7)
ax.set_ylim(-4, 7)
return [hex1, hex2, hex3, hist1, hist2, hist3, hist4,
text1, text2, text3, text4, text5]
# Define loss function comparing PDF(g-r, r-z | M*) and its Fourier pair
# NOTE: Since we plan on jitting, we can't pass comm=comm to our KCalcs.
# Instead, we will be careful to call the compare_*_counts() methods with
# identical randkeys on each MPI rank!
ktrain_lowmass = kdescent.KPretrainer.from_training_data(
training_x[is_noweight_lowmass, :2],
bandwidth_factor=0.3, fourier_range_factor=3.0,
)
ktrain_midmass = kdescent.KPretrainer.from_training_data(
training_x[is_noweight_midmass, :2],
bandwidth_factor=0.3, fourier_range_factor=3.0,
)
ktrain_highmass = kdescent.KPretrainer.from_training_data(
training_x[is_noweight_highmass, :2],
bandwidth_factor=0.3, fourier_range_factor=3.0,
)
kcalc_lowmass = kdescent.KCalc(ktrain_lowmass)
kcalc_midmass = kdescent.KCalc(ktrain_midmass)
kcalc_highmass = kdescent.KCalc(ktrain_highmass)
# Differentiable alternative hard binning in the loss function:
@jax.jit
def soft_tophat(x, low, high, squish=25.0):
"""Approximately return 1 when `low < x < high`, else return 0"""
width = (high - low) / squish
left = jax.nn.sigmoid((x - low) / width)
right = jax.nn.sigmoid((high - x) / width)
return left * right
# NOTE: For multigrad, we have to explicitly define sumstats_from_params()
# and loss_from_sumstats() to replace the old lossfunc()
@jax.jit
def sumstats_from_params(params, randkey):
key1, *keys = jax.random.split(randkey, 7)
model_x, model_w = generate_model(params, randkey=key1)
weight_low = soft_tophat(model_x[:, 2], *lowmass_cut) * model_w
weight_mid = soft_tophat(model_x[:, 2], *midmass_cut) * model_w
weight_high = soft_tophat(model_x[:, 2], *highmass_cut) * model_w
model_low_counts, truth_low_counts = kcalc_lowmass.compare_kde_counts(
keys[0], model_x[:, :2], weight_low)
model_mid_counts, truth_mid_counts = kcalc_midmass.compare_kde_counts(
keys[1], model_x[:, :2], weight_mid)
model_high_counts, truth_high_counts = kcalc_highmass.compare_kde_counts(
keys[2], model_x[:, :2], weight_high)
model_low_fcounts, truth_low_fcounts = kcalc_lowmass.compare_fourier_counts(
keys[3], model_x[:, :2], weight_low)
model_mid_fcounts, truth_mid_fcounts = kcalc_midmass.compare_fourier_counts(
keys[4], model_x[:, :2], weight_mid)
model_high_fcounts, truth_high_fcounts = kcalc_highmass.compare_fourier_counts(
keys[5], model_x[:, :2], weight_high)
# NOTE: "Sumstats" are raw counts so that they can be summed across ranks
sumstats = jnp.array([
*model_low_counts, *model_low_fcounts, weight_low.sum(),
*model_mid_counts, *model_mid_fcounts, weight_mid.sum(),
*model_high_counts, *model_high_fcounts, weight_high.sum(),
])
# NOTE: To prevent *truth* counts being summed, pass them as "auxiliary"
sumstats_aux = jnp.array([
*truth_low_counts, *truth_low_fcounts,
*truth_mid_counts, *truth_mid_fcounts,
*truth_high_counts, *truth_high_fcounts,
])
return sumstats, sumstats_aux
@jax.jit
def loss_from_sumstats(sumstats, sumstats_aux):
# NOTE: Unpack sumstats (raw model counts per kernel + total weight sums)
i = 0
model_low_counts = sumstats[ # slice [0:20]
i:(i := i + kcalc_lowmass.num_eval_kernels)]
model_low_fcounts = sumstats[ # slice [20:40]
i:(i := i + kcalc_lowmass.num_eval_fourier_positions)]
weight_low_sum = sumstats[i:(i := i + 1)][0] # slice [40:41][0]
model_mid_counts = sumstats[ # slice [41:61]
i:(i := i + kcalc_midmass.num_eval_kernels)]
model_mid_fcounts = sumstats[ # slice [61:81]
i:(i := i + kcalc_midmass.num_eval_fourier_positions)]
weight_mid_sum = sumstats[i:(i := i + 1)][0] # slice [81:82][0]
model_high_counts = sumstats[ # slice [82:102]
i:(i := i + kcalc_highmass.num_eval_kernels)]
model_high_fcounts = sumstats[ # slice [102:122]
i:(i := i + kcalc_highmass.num_eval_fourier_positions)]
weight_high_sum = sumstats[i:(i := i + 1)][0] # slice [122:123][0]
# NOTE: Unpack sumstats_aux (raw truth counts per kernel)
i = 0
truth_low_counts = sumstats_aux[ # slice [0:20]
i:(i := i + kcalc_lowmass.num_eval_kernels)]
truth_low_fcounts = sumstats_aux[ # slice [20:40]
i:(i := i + kcalc_lowmass.num_eval_fourier_positions)]
truth_mid_counts = sumstats_aux[ # slice [40:60]
i:(i := i + kcalc_midmass.num_eval_kernels)]
truth_mid_fcounts = sumstats_aux[ # slice [60:80]
i:(i := i + kcalc_midmass.num_eval_fourier_positions)]
truth_high_counts = sumstats_aux[ # slice [80:100]
i:(i := i + kcalc_highmass.num_eval_kernels)]
truth_high_fcounts = sumstats_aux[ # slice [100:120]
i:(i := i + kcalc_highmass.num_eval_fourier_positions)]
# Convert counts to conditional prob: P(krnl | M*) = N(krnl & M*) / N(M*)
model_low_condprob = model_low_counts / (weight_low_sum + 1e-10)
model_mid_condprob = model_mid_counts / (weight_mid_sum + 1e-10)
model_high_condprob = model_high_counts / (weight_high_sum + 1e-10)
truth_low_condprob = truth_low_counts / (training_w_lowmass.sum() + 1e-10)
truth_mid_condprob = truth_mid_counts / (training_w_midmass.sum() + 1e-10)
truth_high_condprob = truth_high_counts / (
training_w_highmass.sum() + 1e-10)
# Convert Fourier counts to "conditional" ECF analogously
model_low_ecf = model_low_fcounts / (weight_low_sum + 1e-10)
model_mid_ecf = model_mid_fcounts / (weight_mid_sum + 1e-10)
model_high_ecf = model_high_fcounts / (weight_high_sum + 1e-10)
truth_low_ecf = truth_low_fcounts / (training_w_lowmass.sum() + 1e-10)
truth_mid_ecf = truth_mid_fcounts / (training_w_midmass.sum() + 1e-10)
truth_high_ecf = truth_high_fcounts / (training_w_highmass.sum() + 1e-10)
# One constraint on number density at the highest stellar mass bin
volume = 100.0
model_massfunc = jnp.array([weight_high_sum,]) / volume
truth_massfunc = jnp.array([training_w_highmass.sum(),]) / volume
# Must abs() the Fourier residuals so that the loss is real
# NOTE: We even have to abs() the PDF residuals due to multigrad
# combining all sumstats into a single complex-typed array
sqerrs = jnp.abs(jnp.concatenate([
(model_low_condprob - truth_low_condprob)**2,
(model_mid_condprob - truth_mid_condprob)**2,
(model_high_condprob - truth_high_condprob)**2,
(model_low_ecf - truth_low_ecf)**2,
(model_mid_ecf - truth_mid_ecf)**2,
(model_high_ecf - truth_high_ecf)**2,
(model_massfunc - truth_massfunc)**2,
]))
return jnp.mean(sqerrs)
# NOTE: Define multigrad class using the sumstats + loss funcs we just defined
@dataclass
class MyModel(multigrad.OnePointModel):
sumstats_func_has_aux: bool = True # override param default set by parent
def calc_partial_sumstats_from_params(self, params, randkey):
# NOTE: sumstats will automatically be summed over all MPI ranks
# before getting passed to calc_loss_from_sumstats. However,
# sumstats_aux will be passed directly without MPI communication
sumstats, sumstats_aux = sumstats_from_params(params, randkey)
return sumstats, sumstats_aux
def calc_loss_from_sumstats(self, sumstats, sumstats_aux, randkey=None):
# NOTE: randkey kwarg must be accepted by BOTH functions or NEITHER
# However, we have no need for it in the loss function
del randkey
loss = loss_from_sumstats(sumstats, sumstats_aux)
return loss
if __name__ == "__main__":
# Run gradient descent (nearly identical to pure kdescent)
model = MyModel()
nsteps = 600
adam_params, _ = model.run_adam(
guess, nsteps=nsteps, param_bounds=bounds,
learning_rate=0.05, randkey=12345)
if not comm.rank:
# Print results and save figure on root rank only
print("Best fit params =", adam_params[-1])
fig = plt.figure(figsize=(20, 9), layout="constrained")
fig.set_facecolor("0.05")
figs = fig.subfigures(1, 2, wspace=0.004)
figs[0].set_facecolor("white")
figs[1].set_facecolor("white")
make_sumstat_plot(
guess, txt="Initial guess", fig=figs[0])
make_sumstat_plot(
adam_params[-1],
txt=f"Solution after {nsteps} evaluations", fig=figs[1])
plt.savefig("kdescent-multigrad-results.png")
else:
# All other ranks need to do this for make_sumstat_plot() to work...
generate_model_into_mass_bins(guess, jax.random.key(13))
generate_model_into_mass_bins(adam_params[-1], jax.random.key(13))
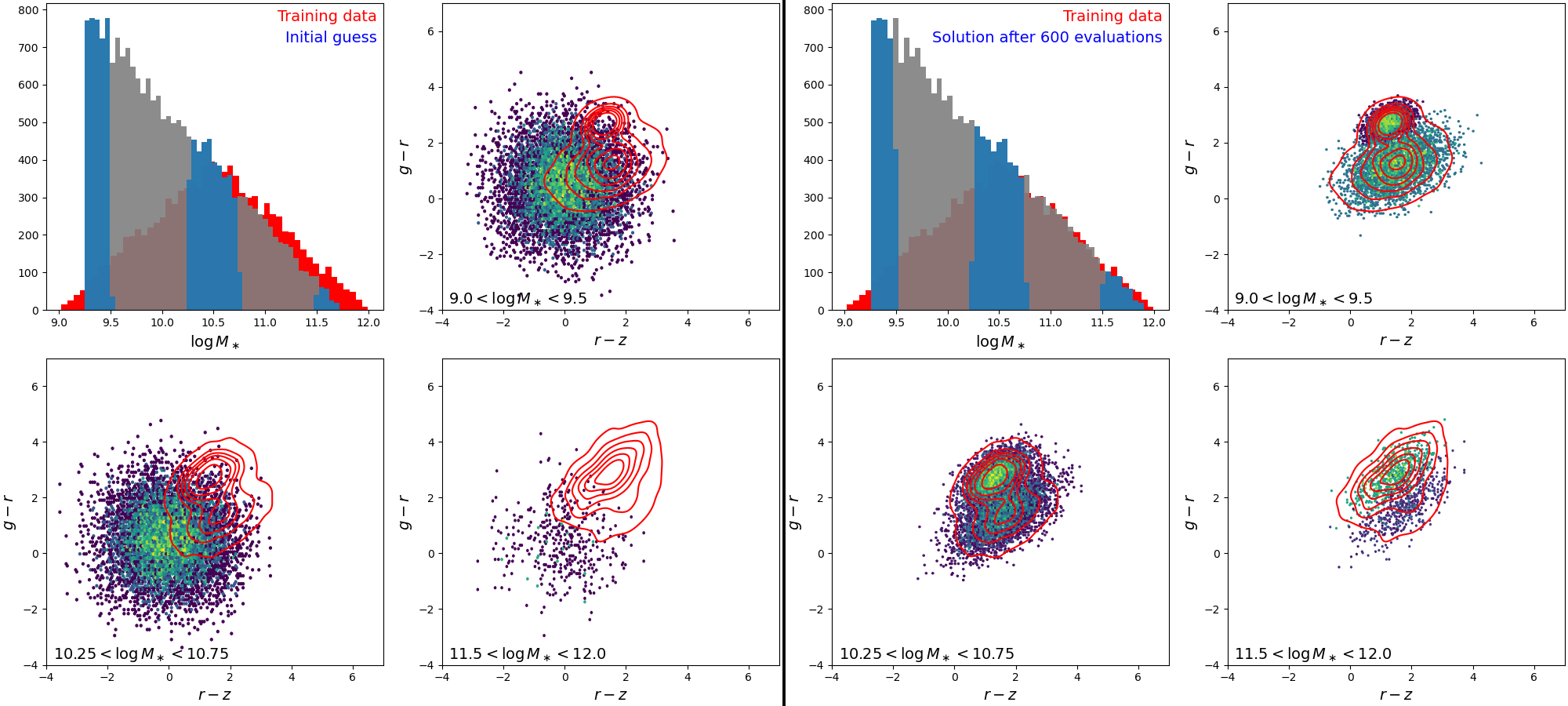
Now let’s run this with four MPI ranks. Executing mpiexec -n 2 python kdescent-multigrad-integration.py yields the following results (about 2x speedup on my laptop):
Adam Gradient Descent Progress: 100%|██████████| 601/601 [04:06<00:00, 2.44it/s]
Best fit params = [ 9.258453 2.6762085 1.486586 1.1471022 0.6167415 0.43723965
0.38919714 0.21205594 -0.2331485 1.5793908 0.40174854 1.7807314
1.7946088 0.56626403 0.58664 0.73132914 0.8944174 -0.34618914
1.080119 0.9135933 ]